Introduction
One of the most common discussion points that come up regularly in interactions with Customers/Prospects/Forums is how does Axon compare to Apache Kafka? Can one do the job of the other? Are they complementary to each other? Can they work together? Does Axon provide any capabilities to work with Kafka?
Axon's fundamental proposition is that it is a platform purpose-built to help implement CQRS and Event Sourcing based architectures - an architecture that advocates the design and development of applications by treating it as a System of Events rather than as a System of State.
So keeping Event Sourcing as the central theme for discussion, this blog post intends to provide clear answers for the above questions. Let us see how we intend to go about this.
What are you going to read about in the next few minutes:
- What is Event Sourcing and how it fits within the Event-Driven Architecture ecosystem:
We elaborate on the principles of Event Sourcing which requires implementation of concepts from Domain-Driven Design, CQRS (Command Query Responsibility Separation), Event Storage and Event Processing. We then deep-dive into the infrastructural components that need to be put in place to implement an Event Sourcing based architecture. - The implementation aspects of these components:
First using Kafka, followed by Axon. At the end of this exercise, we should be able to clearly evaluate the fitment of the two platforms when it comes to implementing Event Sourcing, essentially helping us answer most of the questions raised above. - A case for the complementary nature of the two platforms:
And provide details on how the two platforms can be combined utilizing Axon's support for Kafka.
So, grab your coffee (or tea) and let's begin!
Event-Driven Architectures
The Event-Driven Architecture (EDA) paradigm advocates building applications centered around Generation and Handling of Events.
Although around for a long time it has gone through a renaissance of late due to large scale innovations in this area. This has been primarily driven by the new class of modern applications being built which need to be Reactive in Real-Time, Distributed, and Scalable. These have given rise to new Patterns / Frameworks and Platforms which help build such kinds of applications. One of these patterns that have gained prominence of late is the Event Sourcing Pattern.
Event Sourcing
Originating from the Domain-Driven Design (DDD) world, Event Sourcing advocates the Design and Development of applications by treating it as a System of Events rather than as a System of State.
Event Sourcing mandates that the state of the application should not be explicitly stored in a database but as a series of state-changing events. In DDD, the state of an application is represented by the state of its various Aggregates i.e. Business entities that model the core business logic of an application. Any operation on an Aggregate results in an Event that describes the state change of the Aggregate. This event is stored in a Database in an append-only fashion to the set of Events that might have already occurred for that Aggregate. The current state of an Aggregate is then reconstructed by loading the full history of events from the Database and replaying it.
The Event Sourcing concept is depicted below.
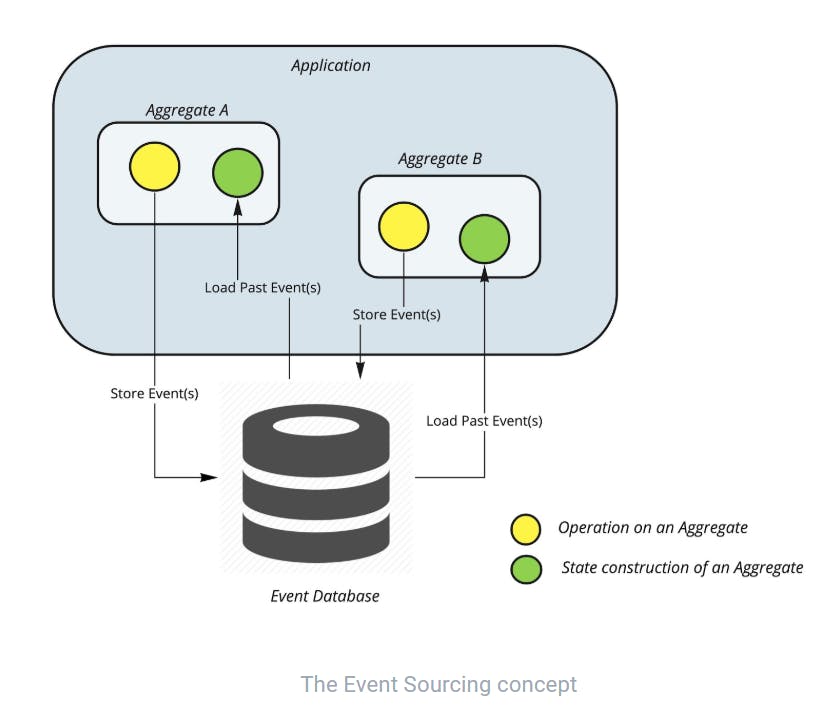
A summary of the benefits of Event Sourcing is listed below,
- Naturalized Audit Trail
- Data Mining / Analytics
- Design Flexibility
- Temporal Reporting
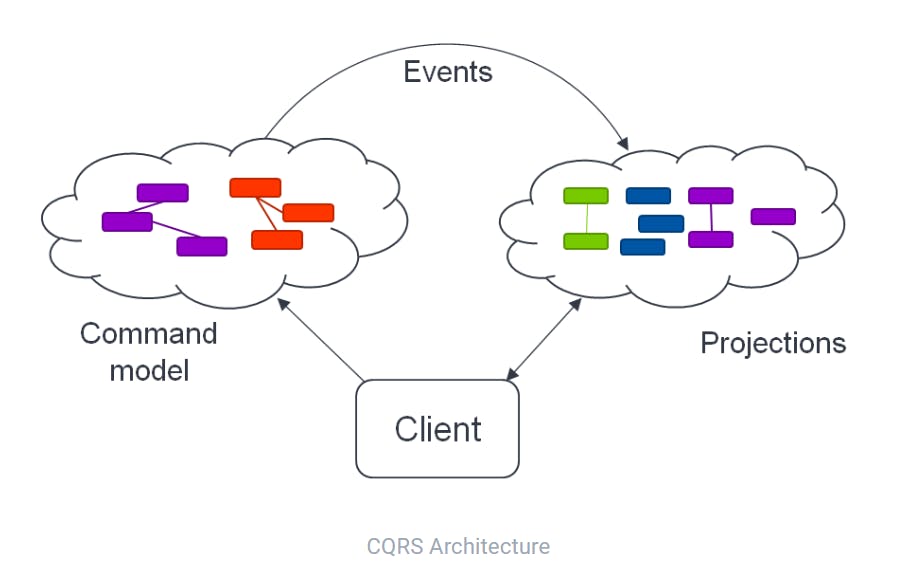
Event Sourcing is almost always used with another pattern: CQRS (Command Query Responsibility Separation). Outside the context of Event Sourcing, CQRS essentially describes the concept of two different models, the Command Model which receives instructions (i.e. Commands) to change application state and the Query(or Read) model which receives instructions (i.e. Queries) to retrieve a certain representation of the current state. Event Sourcing relies on the Command model to process and store the Events as they occur on an Aggregate. The Events are routed to the Query Model which is continuously updated to contain a certain representation of the current state based on these same events. In short, CQRS enables Event Sourcing.
The CQRS pattern is depicted below
To summarize, implementing Event Sourcing involves implementing a set of concerns around Event Storage and Domain-Driven Design and CQRS. Implementing these capabilities in an Event Sourced Architecture is done through the combination of a
- Physical infrastructure i.e. an Event Store which acts as the database for storage of events
- Logical infrastructure i.e. an Application Framework which provides an API to model Aggregates, handle commands/queries and perform event sourcing operations
Let us explore these capabilities in more detail.
Event Store Capabilities
The Event Store needs to adhere to certain core principles which are outlined below:
Append Events
The Event Store needs to be capable of storing the events in an append-only fashion as they occur on the various Aggregates.
In terms of append capabilities, the Event Store needs to provide for the following:
- Consistency - As we append events for an Aggregate into the Event Store, it needs to validate and ensure that the sequence number for the events are stored incrementally with no duplication. The sequencing is critical since the correct construction of the state of the Aggregate requires an ordered read of its events.
- Atomicity - An operation on an Aggregate could result in multiple events. The Event Store has to ensure that all these events are written together or none at all.
- Durability - Committed events in the event store need to be protected against data loss.
- Snapshots - Capability to create and store snapshots for a set of Events of an Aggregate to optimize the state construction phase.
Read Events
The Event Store needs to provide the capability to read the stored events. In terms of read capabilities, the Event Store needs to provide for the following:
- All for an Aggregate - Ability to read all events that have been stored for a specific Aggregate including snapshots if any.
- All since a point in time - Ability to read all events that have been stored since a point in time to help build our query/read models.
- Ad-hoc Queries - Capability to do ad-hoc queries against the Event Store.
- Isolation - Ensuring stored events are only available to read once the transaction is committed to the store.
- Optimization - Optimized to read more recent Events.
Route Events
The Event Store is responsible for routing the Events emitted by Aggregates to interested subscribers. Essentially this capability is similar to that of an Event Bus with support for the required broker capabilities - sync/async modes and guaranteed deliveries.
Scalability
The Event Store needs to provide constant and predictable performance for Appending, Reading, and Routing events as the Event Store grows to potentially billions of events.
Availability & Reliability
The Event Store needs to be highly available and be able to operate in a clustered mode with capabilities for load balancing, automatic/fast failover, and recovery.
Application Framework API Capabilities
The API provided by an Application Framework in an Event Sourcing based architecture provides the necessary capabilities for client applications to interact and perform operations against the Event Store. The API needs to be extremely performant and cater to the extreme demands of scalability.
These capabilities are outlined below:
Aggregate Modeling
Since Event Sourcing deals primarily with Aggregates, the API needs to provide capabilities to model Aggregate stereotypes including the ability to process commands, generate events, and reconstruct an Aggregate’s state based on its past events.
Event Publishing
The API needs to provide capabilities to publish Events to the Event Store such that they recognize the Aggregate as their origin, for event-sourcing that Aggregate instance later on.
Event Handling
The API needs to provide capabilities to receive and process published Events.
Event Replay
The API needs to provide capabilities to replay events from the Event Store to allow a projection to be (re)built from the beginning of the stream, or any arbitrary point in the stream. The order in which events are streamed should be consistent across replays.
Event Versioning
The API needs to provide capabilities to process various versions of Events as they evolve during the lifecycle of an application, without the application’s domain logic needing to be aware of each available version of that event.
Exception Handling
The API needs to provide adequate exception handling capabilities for any event-sourcing operation.
A summary map of all the concerns is depicted below:
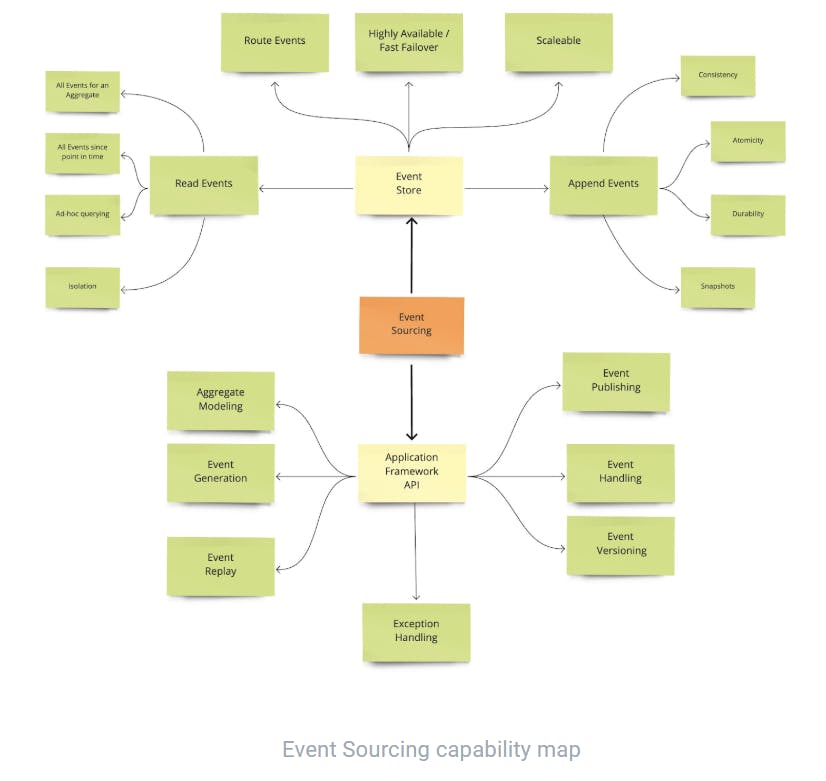
This rounds up this section which detailed out the capabilities that an Event Sourcing Infrastructure needs to provide. The next part of the blog moves onto the implementation of this infrastructure using Kafka and Axon.
Implementing Event Sourcing
Kafka - Event Streaming, not Event Sourcing
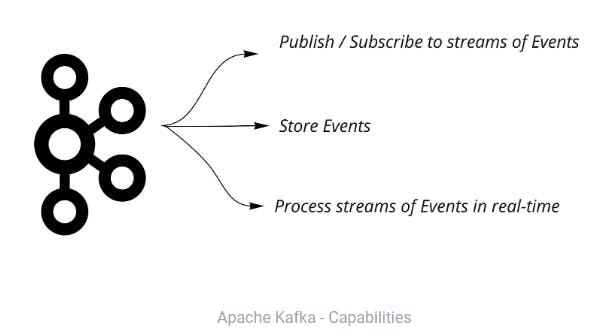
Initially developed at LinkedIn and currently under the Apache foundation, Kafka pioneered the adoption of the concept of Event Streaming which essentially centers around 3 main capabilities:
Implementing Event Sourcing with Kafka requires an optimal design of Kafka topics that serve as the Event Store for appending and reading of Aggregate events. We could start with a basic design of having a single partitioned topic per Aggregate instance. This would guarantee ordered appends for the events and reading the state could be as simple as reading the topic from offset 0. It becomes quite obvious that this would hit problems of scale once we start having millions of Aggregate instances as there will be just too many topics. Another design could be to have a single partitioned topic for all Aggregate types. This causes the reading of events to be extremely slow as the entire data set of Aggregate types and instances need to be scanned.
We could add a database to the mix to provide some of these capabilities but then we would run into the distributed transactions problem to guarantee writes across resources. To solve this issue, we could use another tool from the platform - Kafka Streams. Streams provide the concept of state stores that could store the Aggregate's event stream as snapshots. While this solves the problem of distributed stores as well as the read operations for constructing an Aggregate state, since it only stores the current snapshot, it cannot be used to build your read models.
The API provided by Kafka is limited only to a certain subset of operations required for Event Sourcing (Publishing of Events / Handling of Events). It becomes fairly and quickly obvious that Kafka does not provide us the full range of capabilities to implement an efficient, robust, and scalable Event Sourcing Infrastructure.
Axon - Event Sourcing, and more
Axon is the leading platform built to cater exclusively to implement Event-Driven Architectures, realizing that such architecture requires more than just Events.
In addition to providing a highly scalable Event Store, Axon elevates the concept of traditional CQRS/Event Sourcing architectures by treating every operation within an application (Commands/Queries and Events) as messages. Each of these message types requires a different routing strategy which Axon provides support for.
Axon provides two main components
- Axon Server - A highly scalable, distributed, and purpose-built Event Store and zero-configuration Message Router. It routes messages based on the capabilities each application provided when connecting, taking the specific routing requirements of each type of message into account. Events, which carry value for an extended period of time, are stored for the purpose of Event Sourcing and immediately made available for event streaming.
- Axon Framework - Implements the full range of API capabilities required for Event Sourcing / Message Routing operations. It provides the building blocks required to deal with all the non-functional requirements, allowing developers to focus on the functional aspects of their application instead.
Axon has customers across a wide range of industries who use it to roll out an Enterprise-Grade Event-Driven Microservices infrastructure.
Combining Axon and Kafka
As we have seen above, implementing Event Sourcing from scratch is complex and it does require a purpose-built enterprise-grade platform. At first glance, the Kafka Platform does look like an obvious choice for Event Sourcing, and customers currently utilizing it as their Event Processing Infrastructure see it as a natural extension to support and roll out an Event Sourcing Infrastructure too. But as the various Event Sourcing concerns start getting implemented, it becomes clear that Kafka does not provide it out of the box or simply might not support it. Is this a limitation of Kafka? Absolutely not, Kafka was built with the purpose of being an Event Streaming platform and it shines in that role.
However, we do see enterprises going down the path of extending Kafka to serve the purpose of an Event Sourcing Infrastructure. What it generally leads to is that these non-supported concerns are built around Kafka which might not be a very good idea. These concerns are quite complex which require significant effort, time, and knowledge. Enterprises are better off utilizing a purpose-built platform like Axon for Event Sourcing. It is similar to the choice of utilizing Kafka as your Event Infrastructure, and you are not going to roll out your own!
So do we expect you to just rip-off your Kafka Infrastructure and replace it with Axon? Definitely not! And something which we do not encourage either. Customers rely on Kafka as their central Event Hub and have built an ecosystem of applications around it ranging from Analytics to Integration Services. There is no doubt that the Kafka Platform is the dominant Event Processing Infrastructure in place today.
Axon’s strength is in the application-level messaging, where services need to coordinate their activities on a more detailed level - for example, services that work together in the Order Fulfillment Domain. These activities lead to events, some of which are more important than others. These so-called Milestone Events are typically worth publishing beyond the scope of these cooperating services. That’s where Kafka’s strength is.
To help integrate with Kafka, Axon provides a Kafka-connector as part of the Axon Framework. The purpose of the connector is to help utilize the best of both worlds i.e. use Axon for its purpose-built Event Sourcing Capabilities and Command/Query Message processing while delegating the responsibility of event delivery to downstream systems utilizing Kafka.
The depiction of the integration is shown below with multiple Axon applications relying on Kafka for event delivery to downstream systems
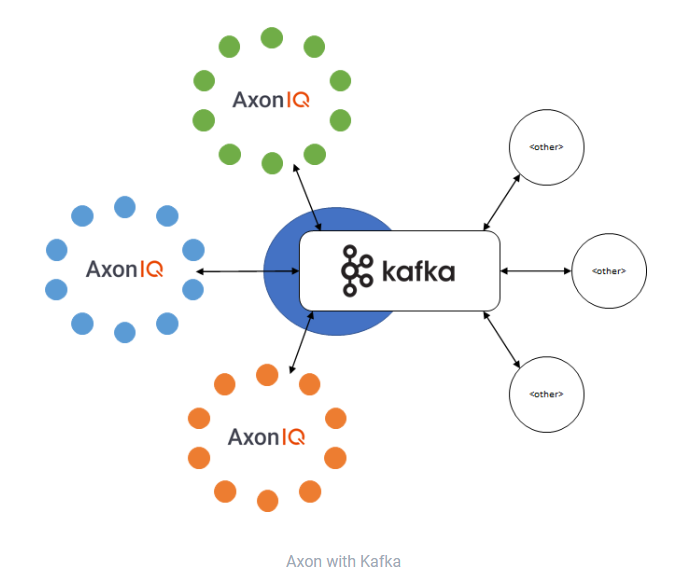
Axon and Kafka - two different purposes
In summary, Axon and Kafka serve two different purposes within the Event-Driven Architecture space - Axon provides the application-level support for domain modeling and Event Sourcing, as well as the routing of Commands, Event and Queries, while Kafka shines as an Event Streaming platform. The combination of both acts as a compelling proposition as it helps customers retain their existing investment in Kafka while at the same time utilizing Axon to roll out a robust, Event-Driven Microservices infrastructure.


