
Reliable Event Scheduling in Distributed Axoniq Systems with JobRunr
How JobRunr integrates with the Axon Framework as an event scheduler, tackling the hard parts of distributed scheduling: persistence, observability, and guaranteed execution.
This guestblog was submitted by our partners at JobRunr. Learn more about their offerings here.
If you are running Axon Framework in production, you have likely hit a point where you need to schedule something to happen in the future. Maybe a payment confirmation needs to arrive within five minutes. Maybe an order should be cancelled if it is not picked up within 24 hours. Maybe a compliance report needs to run at the end of every month.
These are event scheduling problems, and in a distributed system they are harder than they look.
The Scheduling Problem in Distributed Systems
Axon Framework provides the EventScheduler interface for exactly this purpose: schedule an event for future publication. The concept is simple. The implementation challenges are not.
In a single-server setup, you could keep scheduled events in memory. But the moment you move to a distributed architecture with multiple nodes, things get complicated:
Persistence: If a node goes down, in-memory schedules are lost. That payment timeout? Gone. That compliance report? Never fires.
Duplicate execution: With multiple nodes, how do you make sure a scheduled event fires exactly once, not once per node?
Observability: When you have hundreds or thousands of scheduled events across your system, how do you know what is pending, what has fired, and what failed?
These are not hypothetical concerns. They are the exact problems teams run into when they move from development to production with distributed Axon applications.
How JobRunr Solves This
JobRunr is a Java library for background job processing that persists jobs in your existing database. It handles distributed locking, automatic retries, and comes with a built-in dashboard. It also implements Axon's EventScheduler interface through the JobRunrEventScheduler, which means you can drop it into any Axon application.
When you schedule an event through JobRunr's EventScheduler, here is what happens behind the scenes:
JobRunr creates a persisted job in your database with the event payload and the scheduled time
Only one worker across your entire cluster will pick up and execute that job (no duplicates)
If a node goes down before the event fires, another node picks it up automatically
If the event handler fails, JobRunr retries it with an exponential backoff strategy
Here is a practical example. Say you want to publish a TransferDeadlineExpiredEvent if a bank transfer has not completed within five minutes:
That single line gives you a persisted, distributed, observable scheduled event. If the transfer completes before the deadline, you cancel it. If it does not, the event fires and your saga or event handler takes the appropriate compensating action.
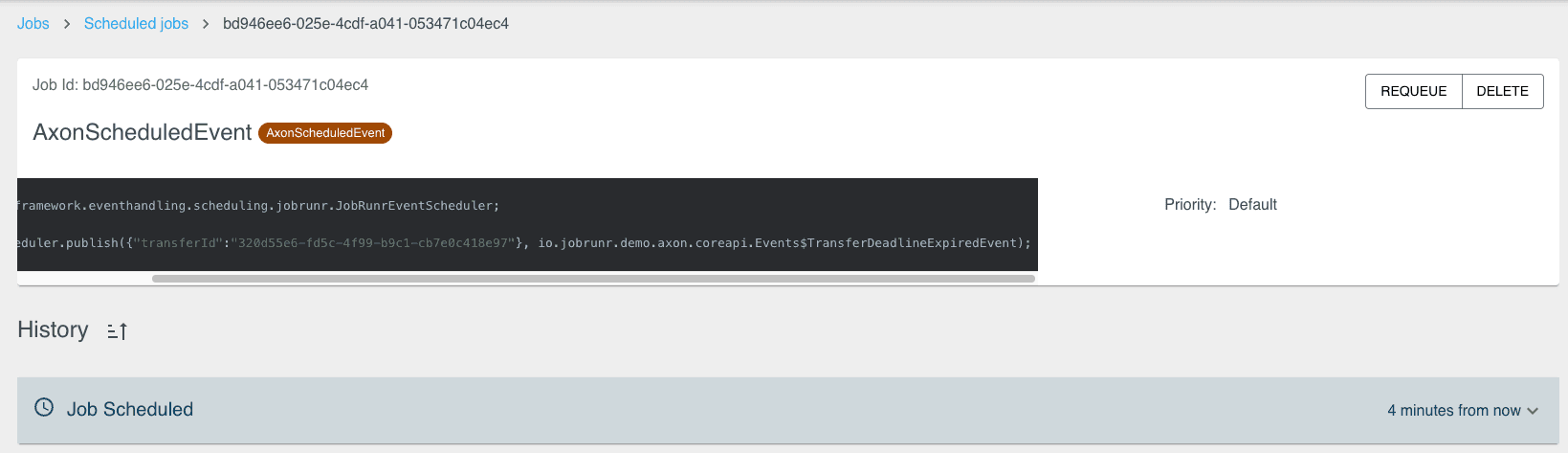
Thanks to JobRunr, you are also able to observe the scheduled event in a dashboard that comes out of the box, on the dashboard you are able to get a concrete overview of what is happening at this time in your system. Once you fire off the scheduled event above, you’ll be able to see it in the “Scheduled” section of the dashboard.

If you click on the job, you can also get more insight as to what it will do when it triggers, which in this case is publishing the TransferDeadlineExpiredEvent.
What You Get Out of the Box
Because JobRunr was built for background job processing at scale, you get capabilities that purpose-built schedulers often lack:
Persistence in your existing database. JobRunr stores jobs in the same database your application already uses. PostgreSQL, MySQL, MariaDB, Oracle, MongoDB, and more are all supported. No separate infrastructure to maintain. If you are already running Axon with an RDBMS event store, JobRunr can share that same database cluster, keeping your operational footprint small.
A real-time dashboard. Every scheduled event is visible in JobRunr's web dashboard. You can see what is scheduled, what is processing, what succeeded, and what failed. For each job you get the full details: when it was created, when it will execute, and what event it will publish. This is not a nice-to-have, it is essential for operating a production system where you need to answer "what happened?" at 2am.
Distributed execution with single-job guarantees. JobRunr ensures that each job is executed by exactly one worker, regardless of how many application nodes you are running. No double-firing, no missed events.
Automatic retries with exponential backoff. If an event handler throws an exception, JobRunr catches it, backs off, and tries again. You configure how many retries you want. Failed jobs are visible on the dashboard with their full stack trace so you can diagnose what went wrong.
Micrometer integration. If you are already using Micrometer for application metrics, JobRunr publishes job-related metrics out of the box: queue depths, processing rates, failure counts. Plug them into Grafana, Datadog, or whatever you already use.
Beyond Event Scheduling: the DeadlineManager
For teams that need tighter integration with the Saga pattern, JobRunr Pro extends this with a full DeadlineManager implementation. Where the EventScheduler publishes events globally to all matching handlers, the DeadlineManager targets a specific saga or aggregate instance, making it the right choice for orchestrating timeouts in long-running business processes.
To give a brief overview of what a Saga pattern is, in case you aren’t familiar with it. A Saga breaks a complex business transaction into a sequence of smaller local transactions, each one of these publishes an event that causes the next step to trigger. If there is a failure in a step then the saga knows to execute compensating actions to undo what was already done.
The key advantage of JobRunr Pro's DeadlineManager over alternatives like Quartz or db-scheduler is how it handles cancellation. In a saga, every step typically schedules a deadline and then cancels it when the expected response arrives. At scale, this means thousands of cancel operations per minute. Quartz handles this by scanning the entire job store. db-scheduler serializes and loops through all tasks. JobRunr Pro uses label-based lookups, making cancellation a direct, indexed operation instead of a full scan.
A comparison of the available DeadlineManager implementations in Axon:
Implementation | Distributed | cancelAll Strategy | Monitoring |
|---|---|---|---|
SimpleDeadlineManager | No (in-memory) | N/A | None |
QuartzDeadlineManager | Possible, not default | Scans all jobs | None built-in |
DbSchedulerDeadlineManager | Yes | Serializes and loops all tasks | Micrometer only |
JobRunrProDeadlineManager | Yes | Direct label lookup | Dashboard + Micrometer + SSO |
Setting it Up
Getting started with JobRunr's EventScheduler in an Axon application takes minimal configuration. Add the dependencies:
With Spring Boot, auto-configuration handles the wiring. The extension picks up the JobScheduler bean and makes the JobRunrEventScheduler (and optionally the JobRunrProDeadlineManager) available for injection. Make sure jobrunr.background-job-server.enabled is set to true in your properties so scheduled events actually get executed.
If you are not using Spring Boot, the builder pattern works too:
A Complete Example: Payment Transfer Saga
To bring everything together, here is a payment transfer saga that uses deadlines at every critical step. Each saga step schedules a deadline. If the expected event arrives in time, the deadline is cancelled and the next step begins. If it does not, the deadline fires and a compensating action rolls back what was already done.
In a system processing 1,000 transfers per minute, this saga creates up to 3,000 deadlines and 3,000 cancellations per minute. The difference between scanning the entire job store for each cancellation versus doing a direct label lookup is the difference between a system that scales and one that does not.
When you are trying this yourself, take a look at the dashboard, watch the events going from scheduled to deleted if everything goes well, and watch them execute if you hit the timeout before the previous step completes.
Why Does This Matter?
When you are giving a demo, the happy path is easy. Everything happens as expected, services respond, events arrive, deadlines get cancelled. But the real world is not as clean as a demo environment, it’s messy, services go down, things don’t get cancelled, and then what? The interesting architecture decisions are made for the failure cases and in industries with high regulation, those failures aren’t just theoretical, they’re what the auditors ask about first.
Combining JobRunr for deadline management and Axon Framework’s event sourcing, we get a powerful solution that gives you an architecture where no matter what happens, everything is traceable and happens as expected, when expected.
Try it Yourself
Clone the demo repository to see this in action. The README walks you through running the example and watching jobs flow through the dashboard in real time.
For more detail on the integration, you can also read our companion article Axon Framework + JobRunr Pro: Saga Deadlines Done Right on the JobRunr blog, which includes a full video walkthrough.
Resources:
Axon Framework deadline managers reference
Event schedulers in Axon Framework
JobRunr Pro Axon extension documentation


" height="300px" id="PUlF9PxPI" transform="translate(146 0)" width="300px"/><path d="M 0 103.917 L 36.942 1.41 L 61.335 1.41 L 98.136 103.917 L 76.281 103.917 L 66.834 76.845 L 22.701 76.845 L 12.831 103.917 Z M 26.79 65.424 L 62.886 65.424 L 45.12 14.523 Z M 171.284 103.917 L 143.789 63.732 L 114.743 103.917 L 99.938 103.917 L 136.598 53.016 L 101.348 1.41 L 126.164 1.41 L 151.826 38.916 L 178.757 1.41 L 193.562 1.41 L 159.017 49.632 L 196.1 103.917 Z M 297.837 52.734 C 297.837 82.908 280.353 105.468 249.051 105.468 C 217.608 105.468 200.265 82.908 200.265 52.734 C 200.265 22.419 217.608 0 249.051 0 C 280.353 0 297.837 22.419 297.837 52.734 Z M 221.274 52.734 C 221.274 72.897 228.465 93.483 249.051 93.483 C 269.637 93.483 276.828 72.897 276.828 52.734 C 276.828 32.43 269.637 11.985 249.051 11.985 C 228.465 11.985 221.274 32.43 221.274 52.734 Z M 405.589 1.41 L 405.589 103.917 L 382.042 103.917 L 333.256 18.471 L 334.243 103.917 L 314.362 103.917 L 314.362 1.41 L 337.909 1.41 L 386.695 86.715 L 385.708 1.41 Z M 430.77 103.917 L 430.77 1.41 L 450.651 1.41 L 450.651 103.917 Z M 573.246 91.932 L 573.246 105.468 L 516 105.468 C 485.544 105.468 468.06 82.344 468.06 52.311 C 468.06 22.842 484.275 0 516.564 0 C 547.02 0 565.491 21.573 565.491 51.747 C 565.491 69.09 557.877 85.305 545.187 95.034 C 554.352 93.201 563.376 91.932 573.246 91.932 Z M 489.069 52.17 C 489.069 75.153 496.965 94.188 516.564 94.188 C 537.432 94.188 544.482 73.038 544.482 52.311 C 544.482 28.764 535.599 11.985 516.564 11.985 C 497.106 11.985 489.069 30.738 489.069 52.17 Z" fill="rgb(0, 0, 0)" height="105.46799999999996px" id="g7P19tPZB" transform="translate(8.294 399.083)" width="573.2455397949218px"/></svg>)